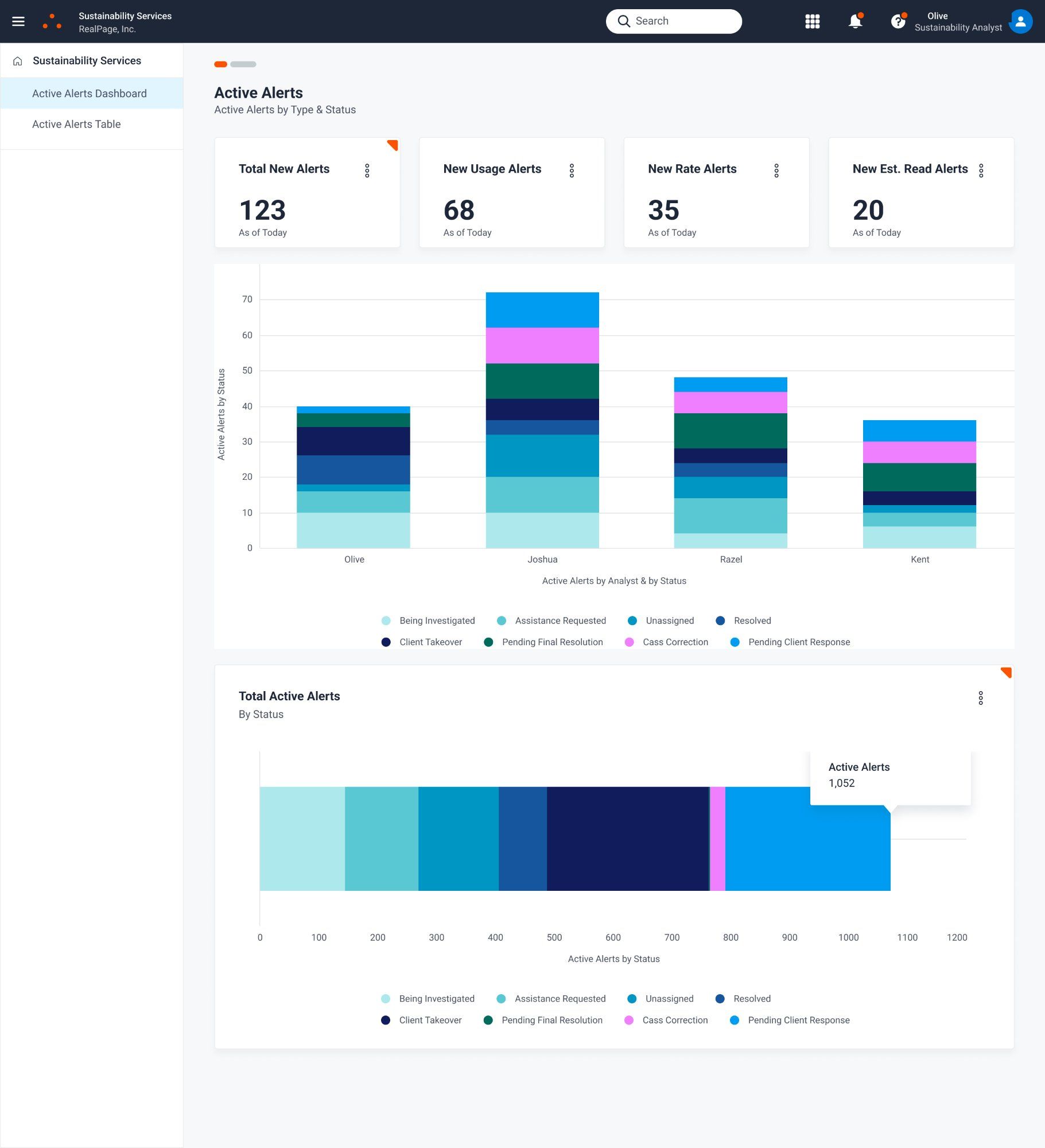
Sustainability Analyst Portal
Research-led redesign to scale an internal utility alert system serving 2,100+ multifamily properties across a distributed four-person analyst team.
Overview
In early 2023, I led research on a stalled initiative at RealPage aimed at dramatically improving the operational efficiency of a small but critical internal team: the Sustainability Analysts. These 4-5 analysts were responsible for reviewing utility usage and expense alerts across more than 2,100 properties, coordinating with facilities personnel from each associated property to investigate and resolve issues.
The business goal was ambitious: 2x or 3x the client base without adding headcount. The existing system was at capacity, buckling under manual workflows, error-prone alert handling, and siloed tools spread across three internal platforms: VES, RBMS, and Simple Bills. There was no automation logic, no batch processing, no shared dashboard, and no effective in-app communication path with clients.
I was brought in to conduct discovery research alongside a proposed solution that was focused exclusively on ruleset and threshold adjustments. Discovery surfaced five additional discrete areas beyond threshold tuning, bringing the total to six, where operational improvements were available. A capacity model built from Power BI time-on-task data showed that acting on these areas, in any combination, could allow the same four-person team to serve 2.5 times as many client properties without adding headcount. Crucially, no single improvement needed to be executed perfectly: modest gains across several areas were enough to reach a meaningful capacity threshold, and more significant gains in one area could compensate for slower progress in another. That resilience made the business case more durable.
What started as a research engagement evolved into a full discovery-to-prototype effort spanning workflow mapping, automation logic, and prototype development. The deliverables span the full fidelity spectrum, from raw synthesis and quantitative modeling through interaction design and prototype validation.
The project was paused before delivery due to leadership turnover. The solutions remain among the most operationally grounded and technically feasible work I've produced.
Research Approach
The work followed a structured progression from workflow discovery through co-design to prototype validation, conducted across a distributed team spanning the US, Philippines, and India.
Phase 1: Workflow Discovery & Stakeholder Immersion
I began by mining hours of prior recorded research sessions, transcribing and coding them to identify patterns, friction points, and decision logic that hadn't been formally documented. This allowed me to ask sharper, more targeted questions in subsequent sessions rather than starting from zero.
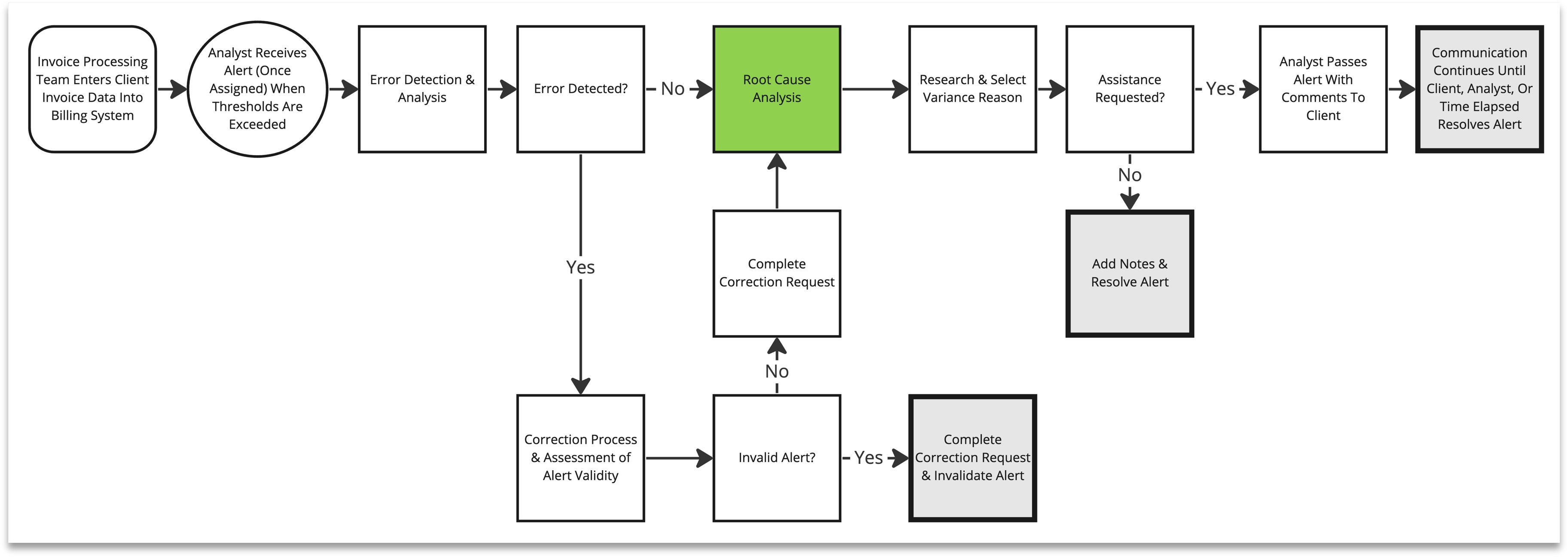
I conducted new stakeholder interviews across three role types: Sustainability Analysts (primary users), the Product Manager, and developers. Across these sessions, I mapped five detailed task journeys organized around the three primary analyst task categories: Error Detection & Correction, Root Cause Analysis, and Alert Resolution. Each journey surfaced distinct failure modes in the existing workflow.
The primary user base was a RealPage team based in the Philippines. Rather than positioning myself as an evaluator, I approached these sessions as a collaborator, focused on listening, making their expertise visible, and building the trust required for candid disclosure of workflow pain.
Phase 2: Operational Analysis & Capacity Modeling
One of the analysts had independently created a Power BI dashboard tracking alert volume and time-on-task metrics. I used this data, alongside interview findings, to construct a Capacity Calculator: a model showing precisely how reductions in alert volume and resolution time would translate to new client support capacity without additional headcount.
This quantified the business case in terms that product and leadership could act on: not just "the workflow is inefficient" but "reducing Standard alert time by 30% and alert volume by 20% creates capacity for X additional properties."
Phase 3: Co-Design & Automation Logic
Working closely with analysts and the developer, I helped codify the implicit decision logic analysts used to triage and route alerts. This became the foundation for proposed automation rules: logic that could handle routine alert classification and routing without analyst intervention.
I co-led the redesign work with a junior designer based in India, providing UX rationale and decision support for layout and interaction patterns. Together we transformed a multi-system workflow into a single UI that honored analyst priorities and practical constraints, including the need for manual override controls to preserve analyst agency during any automation transition.
Phase 4: Prototype Review & Feasibility Confirmation
Redesigned workflows were reviewed with analysts and developers in facilitated sessions. Analysts confirmed that the proposed assignment flow, alert detail view, and dashboard concept addressed the specific inefficiencies they'd described. Developers confirmed that the automation logic was technically feasible within the existing system architecture.
I also facilitated concept testing with end users to validate proposed interaction patterns and refine the direction prior to handoff, which was ultimately paused before full delivery. Analysts were not resistant to automation itself. They were resistant to automation that removed their visibility and decision authority; proposed rules that preserved override controls received consistent approval.
Key Findings
Research surfaced both the immediate operational failures and the systemic conditions that created them.
The Story in Four Panels
The capacity model showed that modest, distributed improvements could unlock significant scaling headroom without adding headcount:
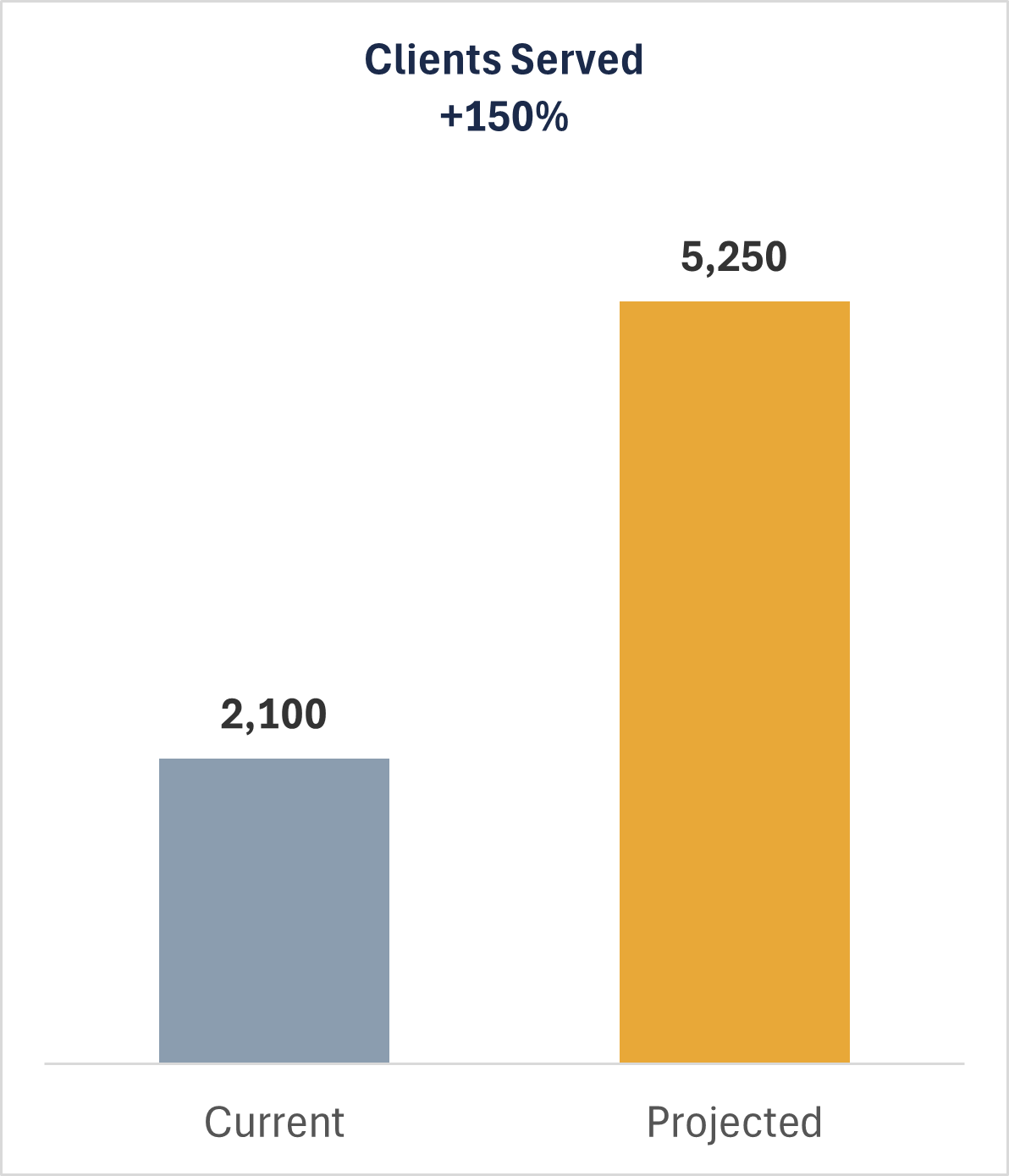
Client Properties Served (+150%)
With design and process changes alone (adjusted rulesets, thresholds, and alert handling workflows), the same 4-analyst team can serve 5,250 client properties, up from 2,100, a 2.5× increase.
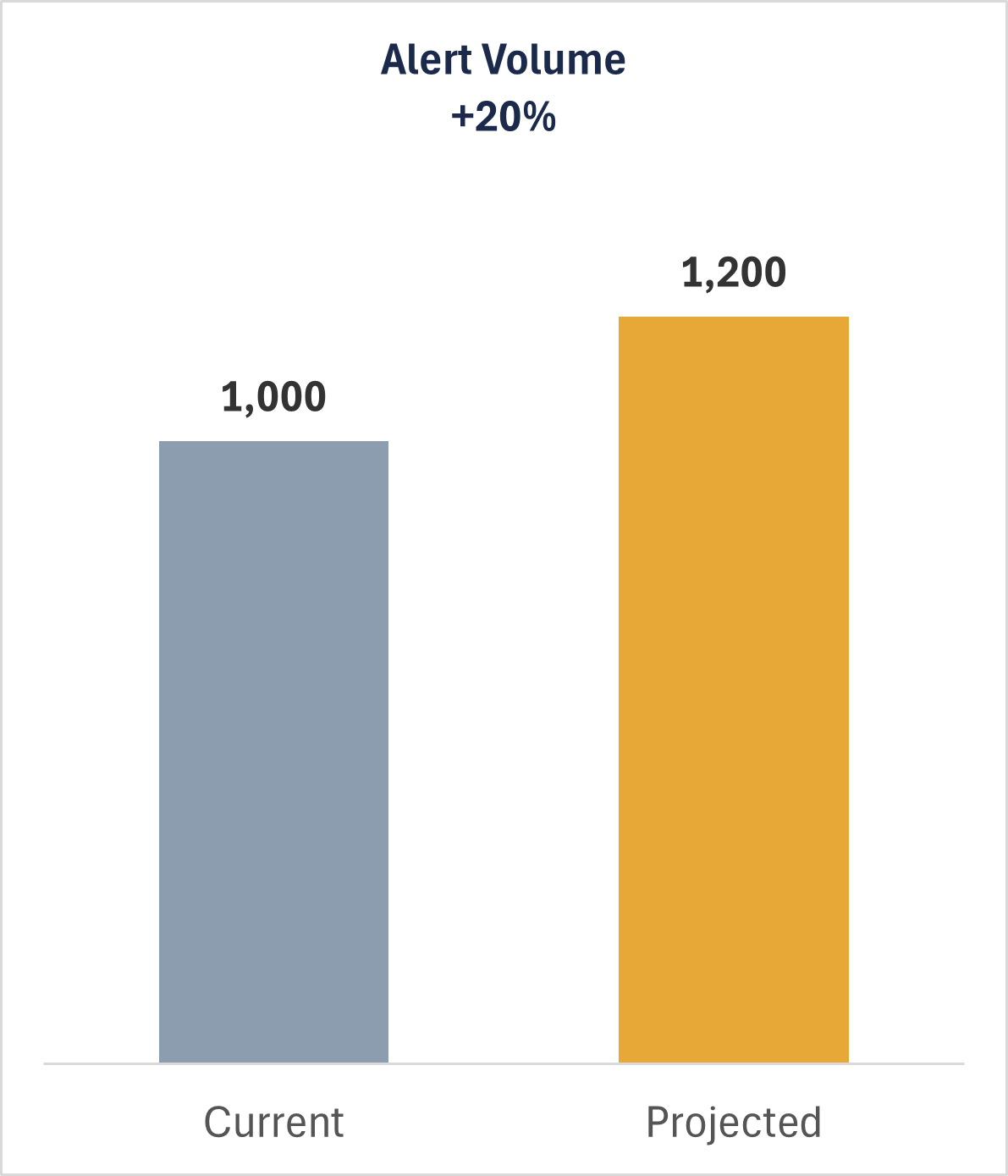
Alert Volume (+20%)
Serving more clients does mean more alerts: 1,200/month vs. 1,000 today. But this is a modest, manageable increase considering the reduced time required per alert.
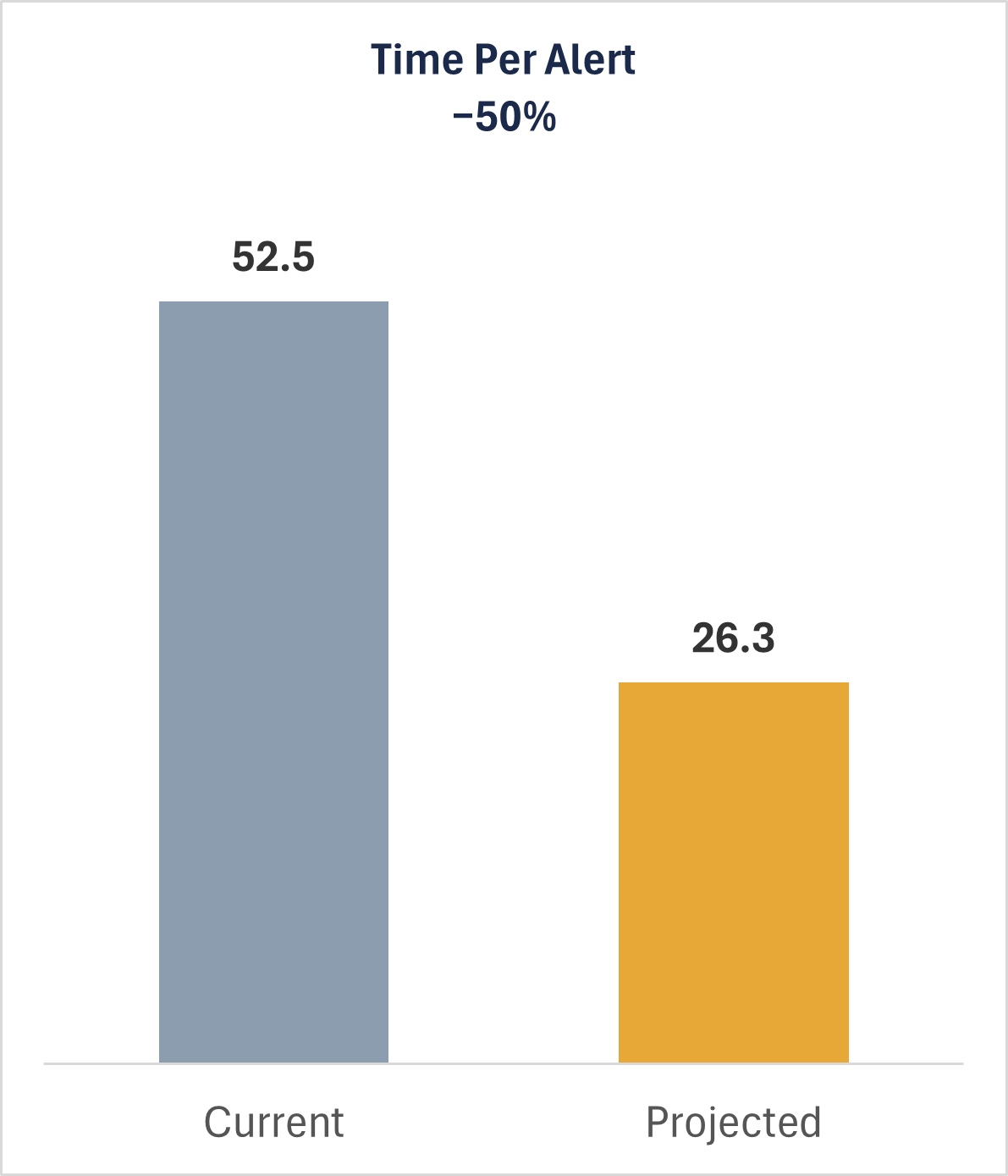
Minutes Per Alert (−50%)
The process improvements cut per-alert handling time in half: from 52.5 minutes down to 26.25 minutes.
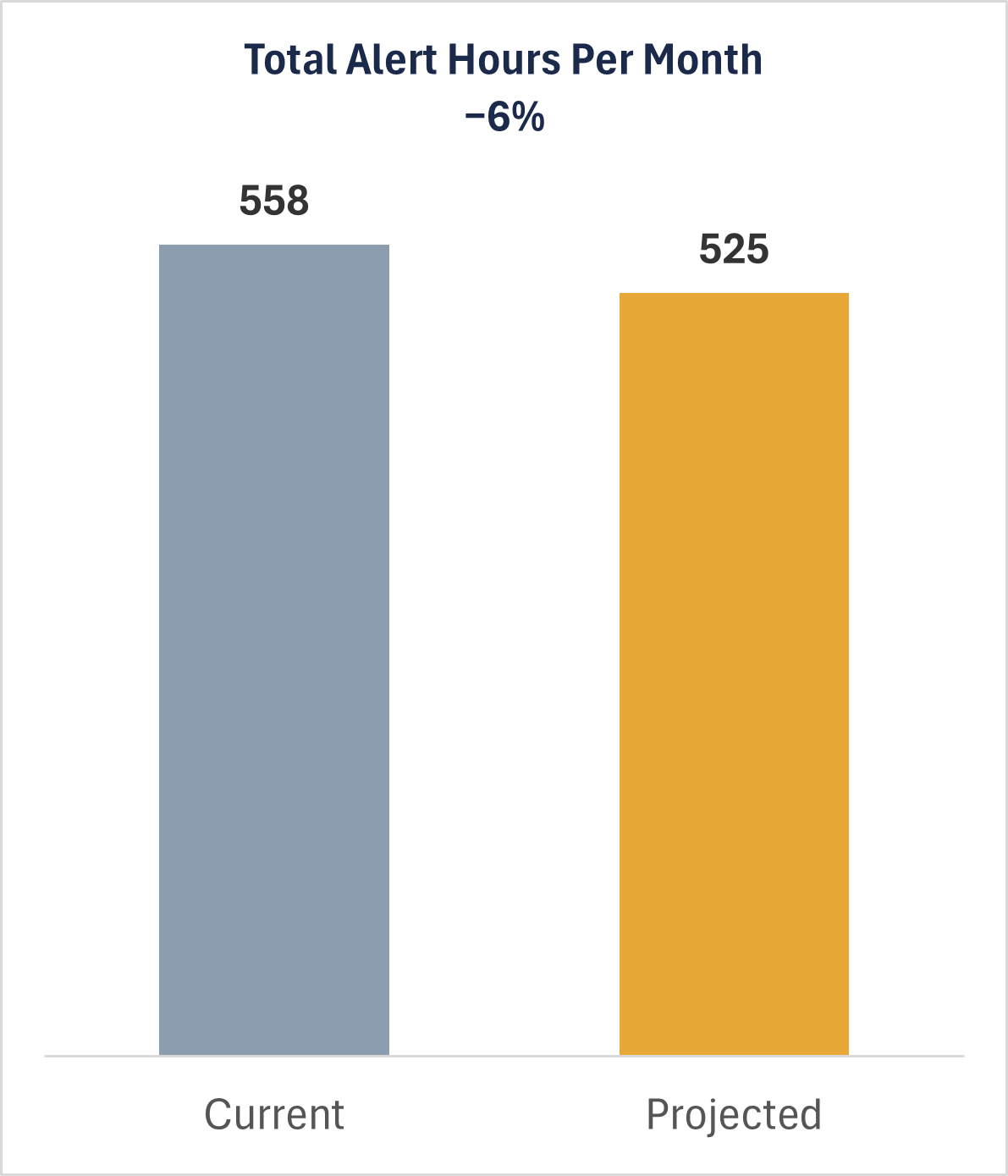
Total Alert Hours / Month (−6%)
The punchline: even with 200 more alerts per month, total analyst time on alerts actually drops from 558 to 525 hours, a net 6% reduction. The efficiency gain more than absorbs the volume increase.
Alert Volume Was Artificially High
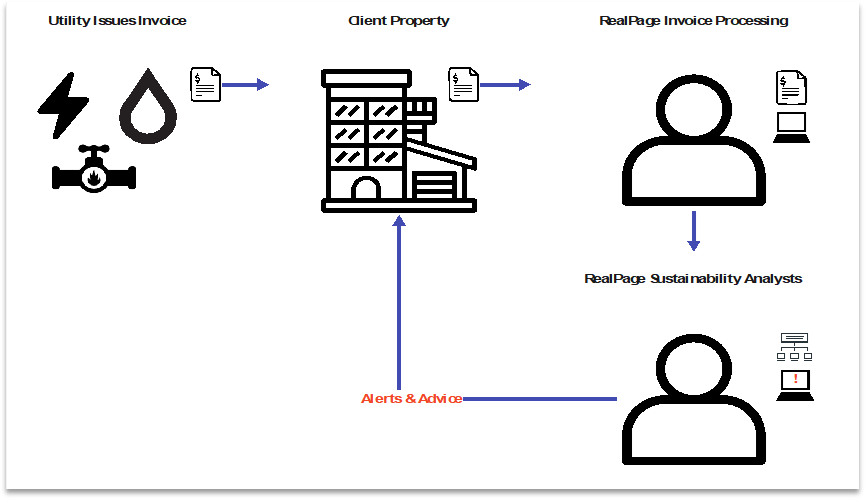
A significant portion of monthly alert volume, roughly 1,000 alerts per month across the team, was driven by upstream data entry errors from the Invoice Processing team, not genuine utility anomalies. Of those 1,000 monthly alerts, 600 were Premium type (averaging 50+ minutes each) and 400 were Standard (averaging 5 minutes each). Premium alerts, the more time-intensive category, were the majority. False positives were consuming analyst time at the same rate as real issues, without any triage mechanism to differentiate them.
Assignment Was a Daily Manual Tax
Each morning, alerts were assigned to individual analysts one-at-a-time. No batch selection existed. No filters existed. No visibility into analyst workload existed. A process that should have taken minutes was consuming disproportionate time daily and creating downstream imbalances in analyst workload that compounded across the week.
Communication Escaped the System
Client communication was initiated inside the platform but continued via email. This created context fragmentation: resolution decisions, client responses, and follow-up actions lived across multiple channels with no linkage to the alert record. Analysts had to manually reconstruct context across every interaction.
No Team Workload Visibility
Outside of a Power BI dashboard one analyst had built independently as a personal workaround, constructed outside any official tooling because the system had never provided this visibility, no one, including the team lead, had real-time insight into alert status, analyst capacity, or aging unresolved items. The absence of a dashboard meant that workload problems could quietly compound for weeks before becoming visible.
Decision Logic Was Tacit and Undocumented
Experienced analysts had internalized a sophisticated triage process for determining whether an alert represented a genuine issue, a data entry error, or a known upstream problem. None of this logic had been formally captured. It existed only in analyst memory, creating fragility, inconsistent handling, and onboarding risk. Documenting this logic was the prerequisite for any automation. The synthesis document produced from this effort was titled, without irony, What on Earth is an Analyst Thinking? It was a working document that translated years of internalized practice into explicit logic the product and development teams could act on.
"The existing workflow required analysts to hold much of the workflow logic in their heads. Tool gaps we found were often a memory burden placed on analysts that could be codified in the system."
Impact & Reflection
The project achieved strong internal alignment and prototype validation before being deprioritized due to leadership turnover. The work did not ship. What was delivered represents a complete research and design foundation ready for development handoff.
What I Delivered
- Five detailed task journey maps covering the full alert lifecycle
- A quantified Capacity Calculator showing how workflow improvements translate to business scaling
- Automation logic documentation codifying analyst triage decision-making
- Redesigned alert assignment flow with batch selection and filtering
- Redesigned alert detail view with integrated error correction and communication
- Draft dashboard concept for real-time workload and alert status visibility
- Analyst and developer confirmation of design direction and technical feasibility
What This Project Reinforced
The value of going upstream. The most important finding, that false positives were artificially inflating alert volume, required examining the process before the analyst's workflow began. Constraining the research to the analyst's immediate experience would have missed it.
The importance of quantification in internal tooling research. Analyst sentiment about inefficiency was compelling but not actionable at the leadership level. Translating that inefficiency into a capacity model, showing exactly what headcount leverage was available, created a business case that abstract UX findings could not.
The need for explicit scope alignment with product management. In retrospect, I can see early signals that the PM's bandwidth and internal positioning weren't stable. More explicit expectation-setting about what executive buy-in required might have created a more durable project foundation.
The reality of distributed team dynamics. Building research credibility with the Philippines-based analyst team required consistent investment in trust before insight was freely shared. Positioning myself as a collaborator rather than an auditor was a deliberate methodological choice that shaped everything else.
AI Readiness
This project is a useful case study in what responsible AI implementation requires. Automation was an explicit goal from the start. But the decision logic that would govern any automated system existed only in the memory of analysts, transferred over time as members were replaced through turnover events. Key decision logic existed only in analyst memory; logic that transferred informally through turnover and invisible to any system that hadn't first sat with the people doing the work.
The resulting synthesis, a structured translation of years of internalized analyst practice into explicit triage logic, became the blueprint for an AI-assisted workflow on this effort. While standard automation might reduce manual steps, this logic-first approach ensured that the automation could actually be trusted in high-stakes environments.
This dynamic is not unique to this project. Most operational environments have meaningful AI leverage available, and most of them haven't done this work yet. Surfacing what's tacit, quantifying what's assumed, and making implicit logic explicit:that's the prerequisite. I can help organizations get there.
Artifacts
Some of the listed items below can be made available for interviews.
- Five task journey maps (alert intake through resolution)
- Capacity Calculator (Excel) : adjustable model showing headcount scaling math
- Automation logic documentation: analyst decision tree for alert triage
- Redesigned alert assignment flow : batch selection and filtering prototype
- Redesigned alert detail view: integrated resolution, error correction, and communication
- Portfolio summary slide deck : produced post-engagement to support interview discussions
Utility Invoice & Alert Route
Sustainability Analyst Workflow
Dashboard Mockup